
First look at rock identification requests at whatsthisrock subreddit
This post is about my ongoing efforts to improve the deep learning part of our mineral identification web app. Unfortunately, there has been less than expected activity at the web app, partly because the mineral identification quality is still clearly subpar. A big factor is with the prediction quality of the deep learning model since it gives the initial list of likely minerals, ranked by their likelihood of being the mineral of the given photo.
One thing I found is that we have several “data problems”:
- Recall can be significantly improved since our DL model only predicts ~1000/5000 mineral classes.
- Looking over our training data shows that there are “dirty” images where a map of where one can find quartz can be labeled as quartz.
- Prediction in the wild can be difficult when people upload images of rocks surrounded by other unrelated objects, or even worse, related objects.
Clearly, the first issue to address is the dirty data problem. However, even before that I decided it might be insightful to analyze our main “client” - the whatsthisrock subreddit.
Returning to the basics:
The main objectives for analyzing the whatsthisrock subreddit include:
- Understand market trends: are there more people asking and answering mineral identification?
- Most frequent minerals: this would help us configure a DL model that targets this mineral distribution first
- How frequent do mineral identification requests get solved?
Data collection:
I collected data through three main sources:
- Pushshift reddit API: to get submission ids of the subreddit over the years 2016 until 2019-12-27 since there is no easy way of scrapping all the submissions over a time period using the official reddit API.
- Reddit API: get all the updated information of the submissions since pushshift do not keep updated data.
- Other sources: get mineral and rock information
In the following, I show two analysis of the collected data related to the defined objectives above. The first one is on the mineral identification requests trend and the rate of identification. The second one is on the distribution of identified minerals and rocks.
Mineral identification requests trend
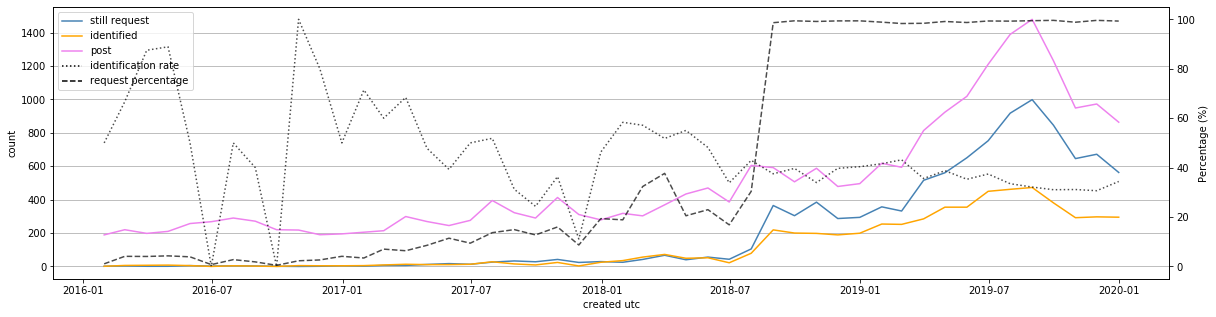
The line plot below shows different trends on the activities of the subreddit. We can see from the violet line of total posts that the number of posts has increased dramatically over the recent years. Furthermore, by comparing the number of requests + identified posts to the number of posts, we can see that a very high percentage of the posts are requests for mineral identification. Currently, almost 100% of the posts are requests for mineral identification. This jump happened at around July 2018 and looking through the posts we can see that this is due to the introduction of an auto moderator (bot) that automatically flags posts as requests if deemed necessary.
By making use of the flair tags where submissions of mineral identification requests are tagged with “request” or “identified”, we can analyzed the percentage of requests that are ultimately resolved.
Out of the 23859 submissions over the years, 15824 submissions have either a “request” or “identified” tag. This seemed to be good enough for moving forward. Below, the 15824 submissions are binned by month and shown over the 4 years. We can see a clear upward trend in terms of mineral identification requests in the recent years. Naturally, the rate of identification has dropped and has been around the 30 - 40% range. This means that our web app can be potentially useful. Of course, it can also be because people did not modified the tags after their rock photo has been identified.
Mineral and rock distribution
Knowing what kinds of minerals and rocks people usually post and are then eventually identified can give insights on the mineral classes that our model should be performing well on and also the mineral classes that potentially exist but are not identified because they are not well-known.
I got a comprehensive list of minerals and rocks from other sources which seem to be a superset of the official IMA list. There are 43932 mineral names and 1432 rock names. Note that they include colloquial or even unapproved mineral names. This will be useful for ensuring robustness as we venture into the NLP (natural language processing) analysis of the reddit data.
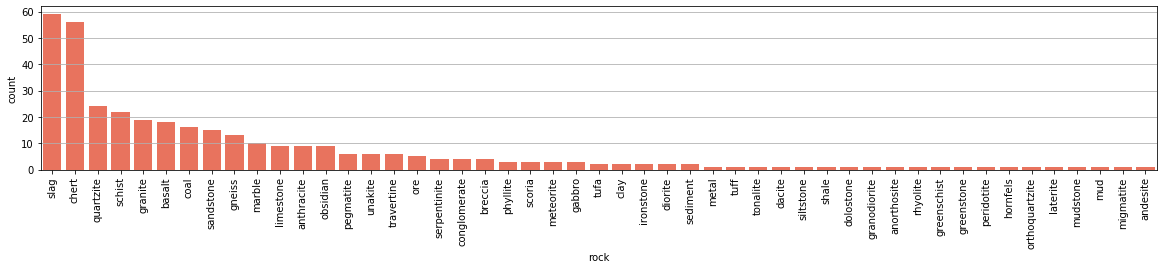
I then filtered the 5733 identified mineral requests and found that in 1274 of the requests, there are more text than just “identified”. Cross referencing with the list of minerals and rocks showed that 1091 of them includes some mention of the identified mineral / rock. Below, the counts of the top 200 identified minerals and rocks are shown. The minerals bar plot is shown in log scale since there are large count discrepancies between the minerals.
Out of the 43932 mineral names, only 223 minerals appeared in the posts and only 49 rock names were included. Moreover, we see that the most frequently identified minerals are agate, calcite, and quartz. For rocks, they are chert and slag.

Next, I will dive into the comments of the submissions to get the distributions of mentioned minerals and rocks. This is a non-trivial task and also kind of an approximation due to all sorts of NLP problems. For example, if someone mentions that he/she found the rock at a place called Diamond Hill, simply finding mineral names would erroneously count diamond. Furthermore, spelling errors might also mess up the counts.